Simplicators
Of the tests that an "Outside-In" TDD process produces, the system tests are responsible for testing the fully integrated system, including its packaging and deployment and its startup and shutdown scripts. The system test process takes the compiled and linked code that has gone through unit testing, packages it up into deployable packages, deploys those packages into a production-like environment, starts the system as it would in production, runs tests against the system's external interfaces, and finally shuts the system down cleanly.
That's all very well unless the the system relies on third-party services, such as other companies' web services or, in large organisations, in-house services that are developed and managed by other departments. The tests need to mock out those services to run reliable, repeatable test scenarios and, since they should run against the integrated system, it's not possible to mock out those services at the code level. The tests need to fake their behaviour at the protocol level.
How easy that is depends on the protocol used to access the service. If we're lucky, the service uses a protocol on which it is is easy to implement a fake service, like HTTP or a message queue. Unfortunately, many services I have to integrate with provide APIs and protocols that are ... how can I put it ... rather byzantine.
A service may use some archaic RPC middleware, publish its endpoints in the enterprise-wide naming service, use a custom TCP protocol hidden behind some awkward binary API, or abuse SOAP so badly that it avoids the few benefits SOAP provides. Whatever, the result is that the service is very difficult to fake out at the protocol level in system tests or even code against in unit tests.
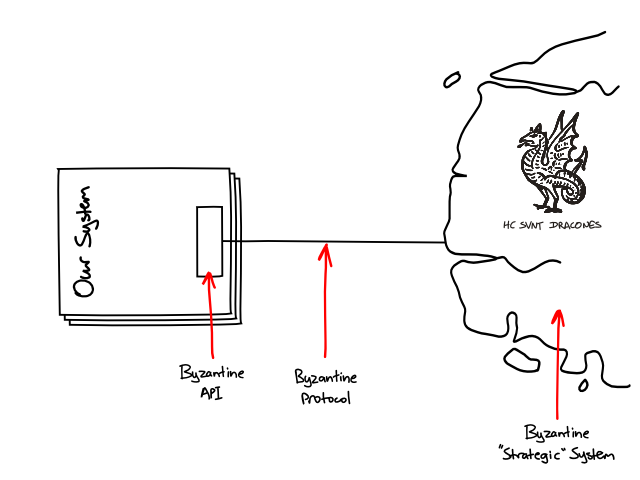
Even at the system scale I find it useful to "listen to the tests", and use the difficulty testing to guide design decisions about the system's architecture.
To deal with a byzantine third-party service, we often introduce what I call a Simplicator: a gateway at the edge of our system that provides a simpler API to the service, shielding the code in our system from the complexities of using the service, and communicates with the rest of the system by an internal protocol that makes it easy to fake the behaviour of the gatewayed service in system tests.
This internal protocol is designed to be easy to change and not inhibit the refactoring and evolution of the rest of the system. We use implementation techniques for the internal protocol that would not be appropriate for a published, inter-application protocol. For example, the simplicator might send data to our system as serialised domain objects that "dematerialise" in our system's processes and do the right thing when invoked. We wouldn't want to expose the serialised form of our domain objects in a published protocol1, but it's very convenient for communication that occurs entirely within the system's boundary and is not persisted between different versions of the system.
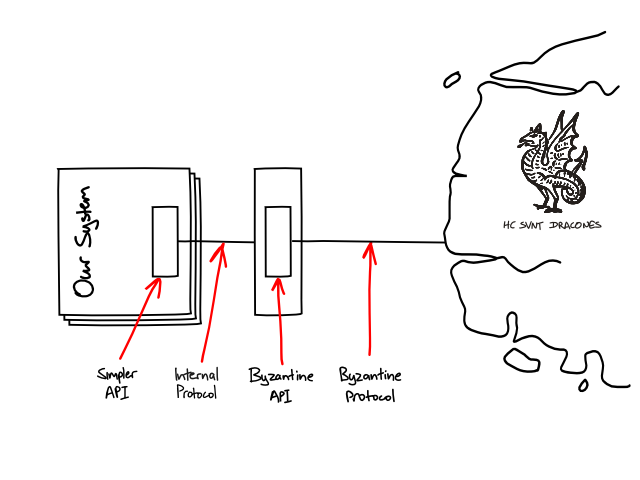
We also design the client-side API, that talks to the Simplicators, to support easy unit testing. I like to test-drive the design of the API itself, using mock objects, so that it is designed in terms of what our code requires from the third-party system, rather than how the third-party system implements its services.
In DDD terms, a Simplicator can act as an Anti-Corruption Layer. However, it's main purpose is not to shield the system's domain model from the model of the third party system but to make it easier to fake the third-party system from the point of view of the tests. It's function as an Anti-Corruption Layer is a happy side-effect.
Faking Simplicators in Tests
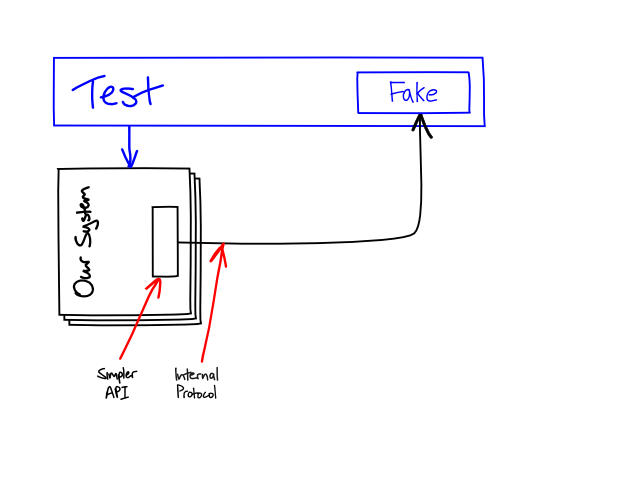
We choose the protocol between the system and the Simplicator to let us easily fake the behaviour of the simplicated services in system tests. When it comes down to it, this is less about the protocol itself than the availability of libraries that let us easily embed the server-side protocol endpoints in our tests as well as in the Simplicator service we will deploy in production.
Ideally, the same implementation of the Simplicator's protocol will be used in both the production Simplicator service and the system tests. In the system tests we will plug it into a mock implementation of the service that we prime with canned data for the test and, if necessary, will verify the interactions of the system with the simplicated service.
For example, if we're building our simple protocol on top of HTTP, the Simplicator's protocol will be implemented as one or more servlets that translate HTTP requests into calls to some service interface that we define for the Simplicator. In our system tests we can instantiate those servlets with a fake implementation of the service and run them in an embedded HTTP server.
If the Simplicator serves serialised domain objects, then it's very easy to create that canned data, especially if we have already implemented Test Data Builders for those objects.
External Service Tests through Simplicators
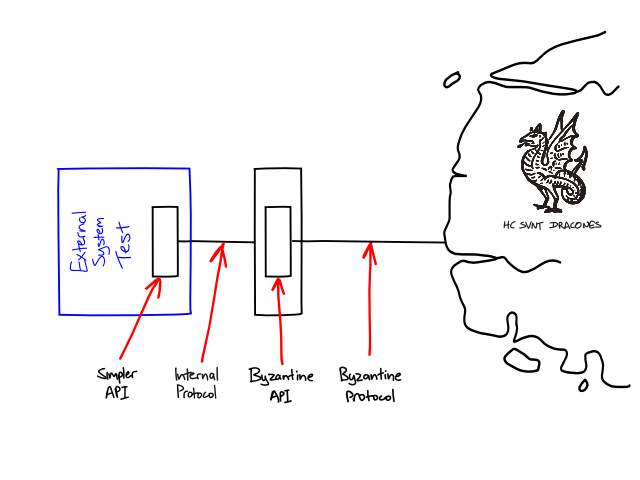
Because our system tests fake out the Simplicators, they only cover the protocol implementation of the Simplicator and not the code that interfaces with the third-party service. Indeed, the Simplicators exist so that we can test the rest of our system without depending on awkward third-party services. That leaves the question: do our Simplicators interface with the third-party services correctly?
To check this, we run a separate suite of External System Tests: Integration Contract Tests that test the Simplicators against a real instance of the external service by running requests through the client-side API, simple protocol, and the Simplicator itself. This verifies that our Simplicator integrates correctly with the external service and that real requests and responses can be passed correctly through our simple protocol and client API.
I prefer to run external system tests against the production instance of the external service, but when that's not possible the external system tests run against a stable environment that the team developing the service provide for integration testing. 2 The behaviour of the External System Tests are not fully under our control, relying as they do on the remote environment being available and working correctly. Therefore, we don't usually treat them in the same way as our other tests. We won't promote a build to production if the External System Tests have failed, because we don't know if it will work, but we won't let failures in the External System Test suite stop us checking in changes to our own code if the suites that are fully under our control are still passing.
We run the External System Tests on every check-in to catch any changes we have made that are incompatible with the remote service. We also run them on a regular schedule (every night at 2am, for example) to detect if the team writing the service have changed it and broken our system.
On one project, our External System Tests became part of the release process of the systems we depended on. A release could only be promoted to production if our external system tests running against their prerelease environment were passing. This really helped smooth the integration between the two systems because we didn't have to schedule periods of coordinated testing before their releases. Our External System Tests verified that new versions of their service still met the contract we depended on.
Added Benefits
A Simplicator introduces a new seam into the system that did not exist when the service's byzantine API was used directly. As well helping us test the system, I've noticed that this seam is ideal for monitoring and regularing our systems' use of external services. If a widely supported protocol is used, we can do this with off-the-shelf components.
For example, if a Simplicator serves data to our system by HTTP, we can easily insert a caching proxy between the system and the Simplicator and make the Simplicator send cache control headers on its responses. This reduces our demand on the external service as we add processes and machines. Caching proxies provide lots of helpful diagnostics that have helped us understand and tune system performance and understand the performance characteristics of external systems.
Footnotes
- I've seen systems that did just that and were unmaintainable because their internal implementation could not be changed without breaking other systems.
- An environment used for testing new releases of the external system is not suitable for running External System Tests that verify that clients integrate correctly with the system3.
- Except in "pregression" tests, which I'll write about another time.